
RAG Paradigms
Naive RAG, Advanced RAG and Modular RAG

We discussed RAG in article Retrieval Augmented Generation(RAG). Let’s see some patterns for RAG in this article.
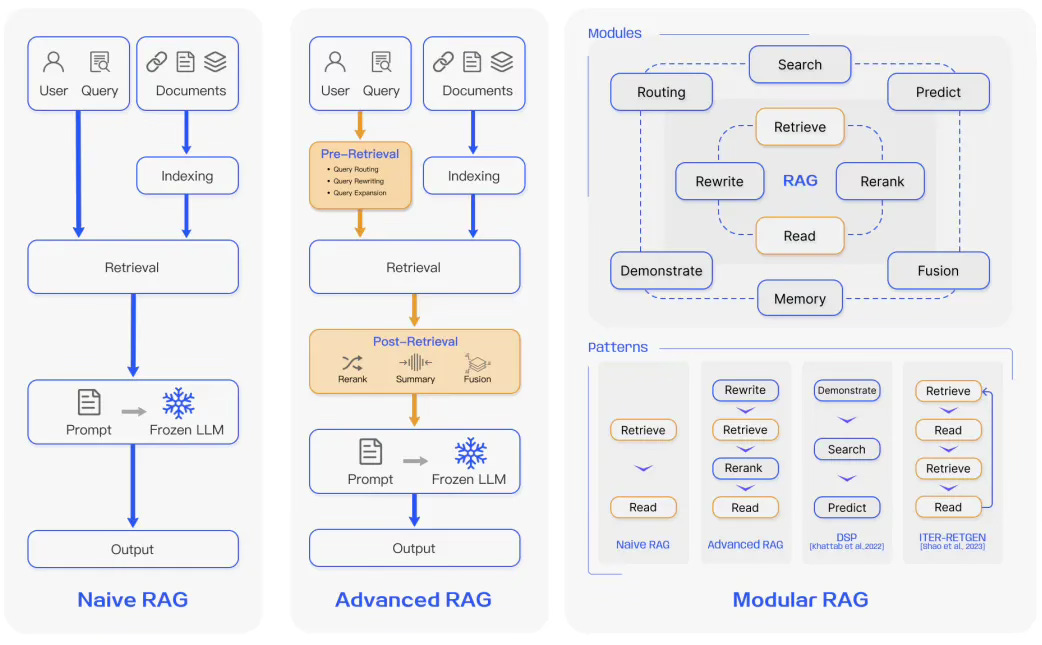
Naive RAG
Naive RAG follows the traditional aforementioned process of indexing, retrieval, and generation. In short, a user input is used to query relevant documents which are then combined with a prompt and passed to the model to generate a final response. Conversational history can be integrated into the prompt if the application involves multi-turn dialogue interactions. See example in Kaggle RAG by Leveraging Vector DB and LLMs and Integrating Vector DB with LLMs.
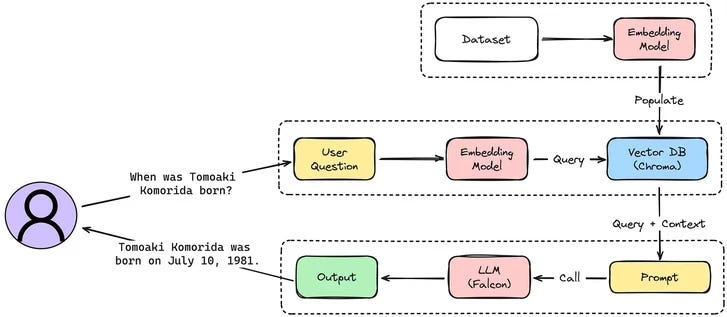
The illustration above is what we did in the Kaggle notebook. It is work well. However, it has limitations such as low precision (misaligned retrieved chunks) and low recall(failure to retrieve all relevant chunks). It’s also possible that the LLM is passed outdated information which is one of the main issues that a RAG system should initially aim to solve. This leads to hallucination issues and poor and inaccurate responses.
When augmentation is applied, there could also be issues with redundancy and repetition. When using multiple retrieved passages, ranking and reconciling style/tone are also key. Another challenge is ensuring that the generation task doesn’t overly depend on the augmented information which can lead to the model just reiterating the retrieved content.
Advanced RAG
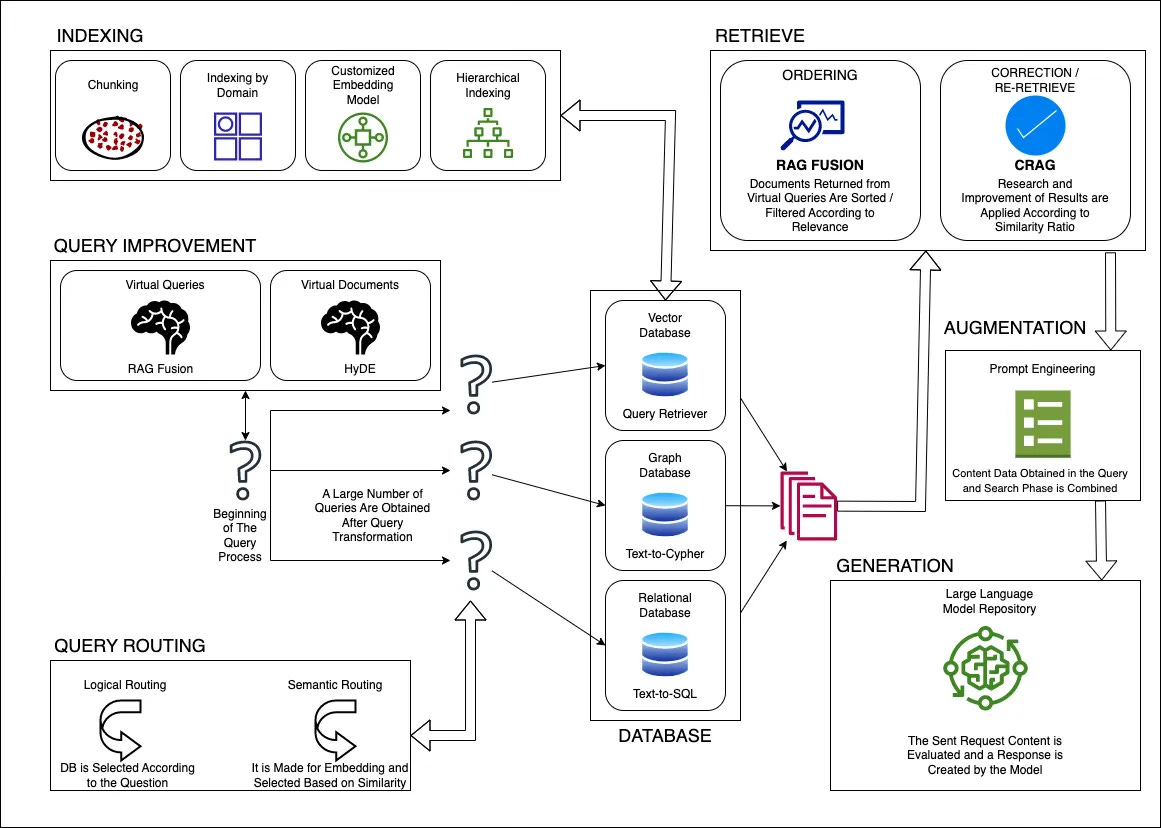
It improving retrieval quality that could involve optimizing:
pre-retrieval
retrieval
post-retrieval
Pre-retrieval
The pre-retrieval process involves optimizing data indexing which aims to enhance the quality of data being indexed through five stages:
Enhancing data granularity
Optimizing index structures
Adding metadata
Alignment optimization
Mixed retrieval
Retrieval
The retrieval stage can be further improved by optimizing the embedding model itself which directly impacts the quality of the chunks the make up the context. This can be done by fine-tuning the embedding to optimise retrieval relevance or employing dynamic embeddings that better capture contextual understanding.
Vector store index
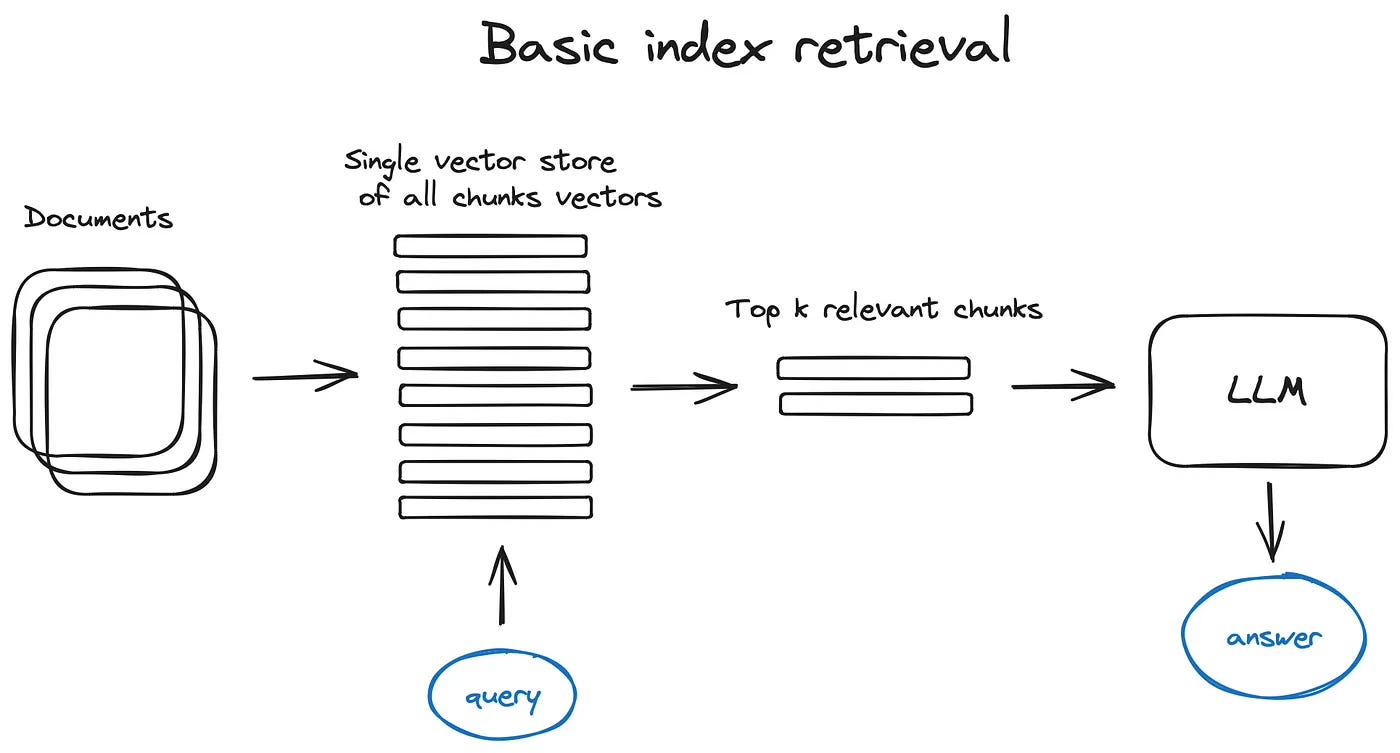
The crucial part of the RAG pipeline is the search index, storing the vectorised content. The most naive implementation uses a flat index - a brute force distance calculation between the query vector and all the chunk’s vectors.
A proper search index, optimised for efficient retrieval on 10000+ elements scales is a vector index like:
using some Approximate Nearest Neighbours implementation like clustering, trees or HNSW algorithm. There are also managed solutions like OpenSearch or ElasticSearch and vector databases, taking care of the data ingestion pipeline.
Hierarchical indices
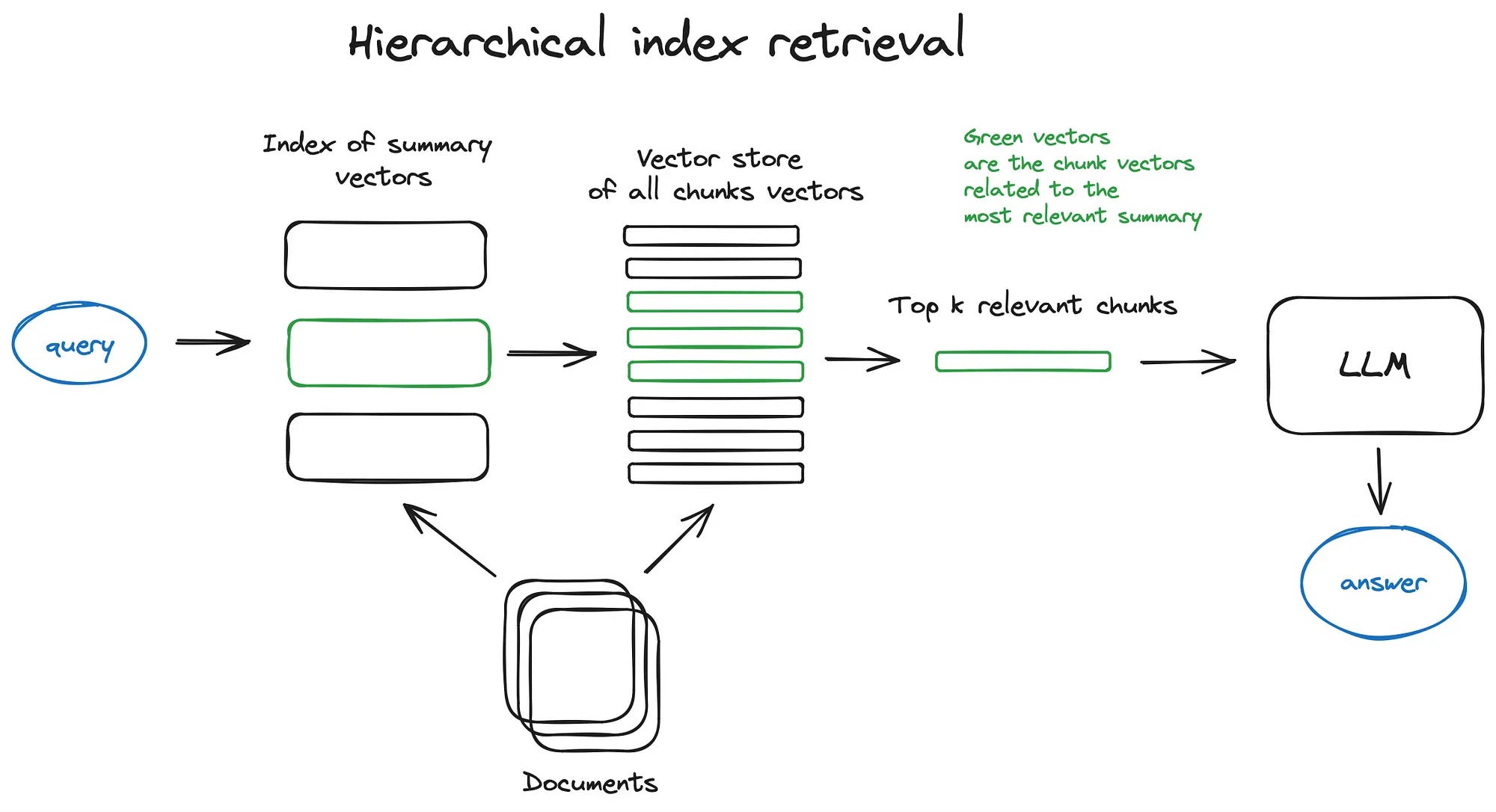
In case we have many documents to retrieve from, we need to be able to efficiently search inside them, find relevant information and synthesise it in a single answer with references to the sources. One of the efficient ways to do that in case of a large database is to create two indices — one composed of summaries and the other one composed of document chunks, and to search in two steps, first filtering out the relevant docs by summaries and then searching just inside this relevant group.
CRAG
It is an approach, developed as a solution to the verifying or improving search results. It is set up to classify the results as ‘true’, ‘false’ or ‘unclear’ results by defining an upper and lower threshold value for all search results. Paper
Self-RAG
Self-RAG is a related approach with several other interesting RAG ideas (paper). The framework trains an LLM to generate self-reflection tokens that govern various stages in the RAG process
Post-retrieval
Post-retrieval focuses on avoiding context window limits and dealing with noisy of potentially distracting information. A common approach to address these issues is re-ranking which could involve approaches such as relocation of relevant context to the edges of the prompt to recalculating the semantic similarity between the query and relevant text chunks. Prompt compression may also help in dealing with these issues.
Modular RAG
As the name implies, Modular RAG enhances functional modules such as incorporating a search module for similarity retrieval and applying fine-tuning in the retriever. Both Naive RAG and Advanced RAG are special cases of Modular RAG and are made up of fixed modules. Extended RAG modules include:
search
memory
fusion
routing
predict
task adapter
which solve different problems.
Fusion
It overcomes the inherent limitations of RAG by creating multiple user queries and reordering the results. It aims to bridge the gap between what users explicitly ask and what they want to ask, moving closer to uncovering transformative knowledge that often remains hidden. To put it more simply, think of RAG Fusion as the person who insists on getting everyone’s opinion before making a decision.
Reciprocal Ranking Fusion(RRF)
It is a technique for combining the rankings of multiple search result lists to create a single combined ranking.
These modules can be rearranged to suit specific problem contexts. Therefore, Modular RAG benefits from greater diversity and flexibility in that you can add or replace modules or adjust the flow between modules based on task requirements.
Given the increased flexibility in building RAG systems, other important optimisation techniques have been proposed to optimise RAG pipelines including:
Hybrid Search Exploration
This approach leverages a combination of search techniques like keyword-based search and semantic search to retrieve relevant and context-rich information; this is useful when dealing with different query types and information needs.
Recursive Retrieval and Query Engine
Involves a recursive retrieval process that might start with small semantic chunks and subsequently retrieve larger chunks that enrich the context; this is useful to balance efficiency and context-rich information.
StepBack-prompt
A prompting technique that enables LLMs to perform abstraction that produces concepts and principles that guide reasoning; this leads to better-grounded responses when adopted to a RAG framework because the LLM moves away from specific instances and is allowed to reason more broadly if needed.
Sub-Queries
There are different query strategies such as tree queries or sequential querying of chunks that can be used for different scenarios. LLamaIndex offers a sub question query engine that allows a query to be broken down into several questions that use different relevant data sources.
Hypothetical Document Embeddings
HyDE generates a hypothetical answer to a query, embeds it, and uses it to retrieve documents similar to the hypothetical answer as opposed to using the query directly.
Conclusion
For naive RAG, it works well in some cases but it has limitations, like low precision and low recall. And we show two examples(Vector DB+LLMs).
For advanced RAG, it has three strategies to help optimizing retrieval processes. For example, we do embeddings in examples are mentioned above by using SentenceTransformers. We can have own fine-tuned Encoder model if necessary.
For modular RAG, we use HuggingFace RAG model can embed any other retrievers and generators. And it is also embed Facebook Faiss by default. We use HuggingFace RAG model embed Faiss algorithm to do efficient similarity search.
I believe these patterns are not conflict with each other. They can be worked together or separately as the specific necessary.
Note: All the illustrations come from Acknowledge section and I credit them.
Acknowledge
https://www.kaggle.com/code/aisuko/semantic-search-in-publications
https://www.kaggle.com/code/aisuko/titanic-question-with-tf-decision-forests
https://www.kaggle.com/code/aisuko/llm-prompt-recovery-with-gemma
https://github.com/facebookresearch/faiss
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
https://ugurozker.medium.com/advanced-rag-architecture-b9f8a26e2608