
Mixture of Expert(MOE) Architecture
Is it has a big future?

There are several methods of be able to reduce the cost of inference of a model. Not all the parameters are needed in the model, so after training one could thin out the weights that are no longer useful. So, the most commonly used techniques to reduce the memory footprint and computational cost of an LLM are:
Quantization
Pruning
It is the elimination of weights that are considered unimportant without affecting performance too much
Knowledge distillation
It leverages the knowledge of an LLM to train a much smaller and more specialised model.
These techniques are applied to models after training, there is research that focuses on changing the structure of the model to make it more efficient:
Combat architecture design
It is a method to try to replace self-attention(the most expensive component of the model)
Dynamic networks
It in which only certain substructures are active at a given time, such as a Mixture of Experts
Mixture of Experts
It enables models to be pretrained with fat less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining. And it has two main elements:
Sparse MoE layers
These layers are used instead of sense feed-forward(FFN) layers. MoE layers have a certain number of “experts“ where each expert is a neural network. In practice, the experts are FFNs, but they can also more m]complex networks or even a MoE itself, learning to hierarchical MoEs.
A gate network or router
It determines which tokens are sent to which expert. For example, in the image below, the token “More“ is sent to the second expert, and the token Parameters is sent to the first network, As we will explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
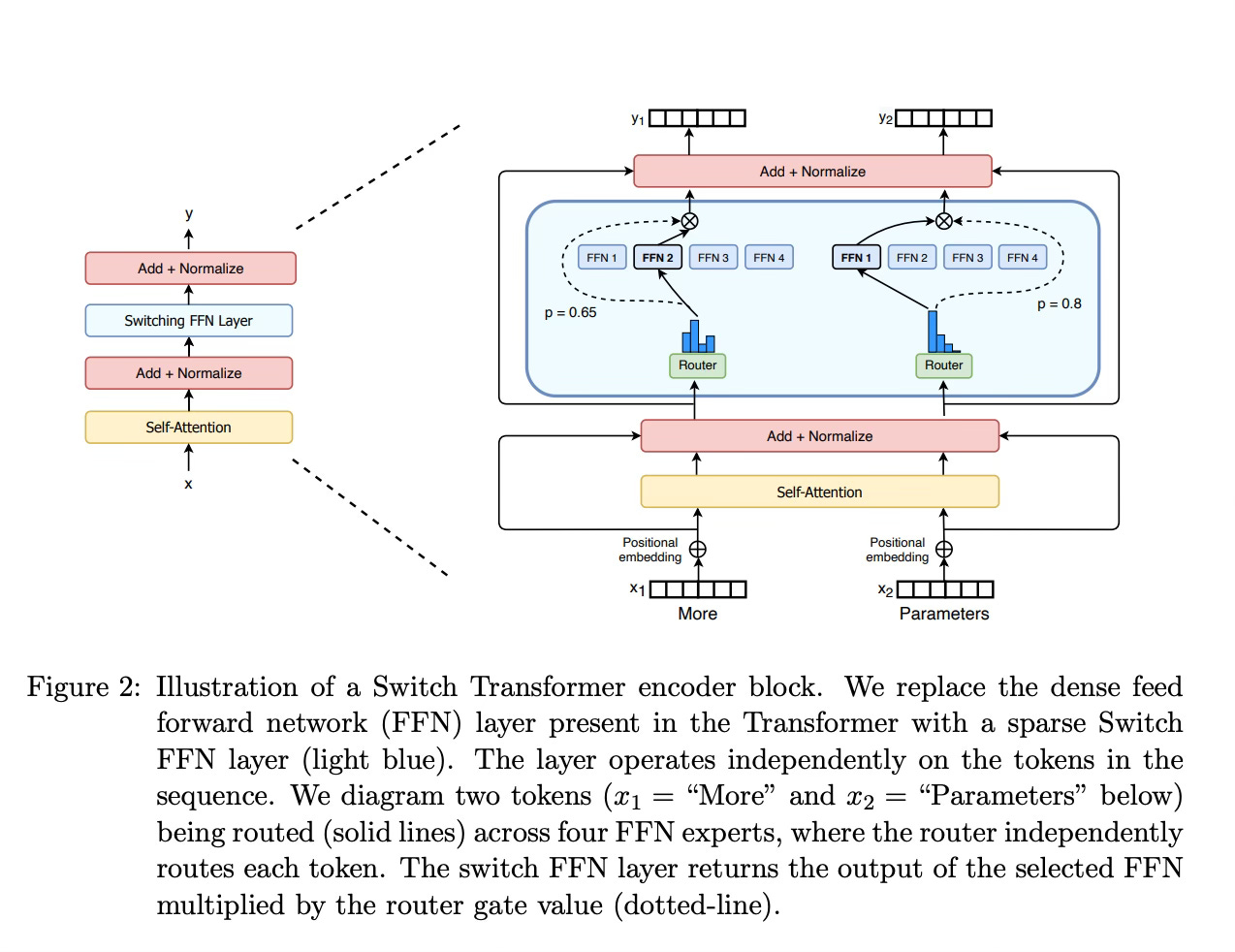
As it mentions, they replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Challenges
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
Training
MoEs enable significantly more compute-efficient pretrainin, but they’re history struggled to generalise during fine-tuning, leading to overfitting.
Inference
Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a sense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high.
For example, we need to have enough memory to hold a sense 47B parameter model to run inference with Mixtral 8x7B rather than 8x7=56. This is because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared.
At the same time, assuming just two experts are being used per token, the inference speed(FLOPs) is like using a 12B model, because it computes 2x7B matrix multiplications, but with some layers shared.
Summary
MoEs are pretrained much faster than denser models. It have faster inference compared to a model with the same number of parameters. However, it requires high VRAM as all experts are loaded in memeory. Furthermore, it also faces many challenges in fine-tuning.
Acknowledge
https://levelup.gitconnected.com/llm-redundancy-it-is-time-for-a-massive-layoff-of-layers-948827aa926e
https://huggingface.co/blog/moe